Table of Content
- How Modern Text-to-Video Generation Actually Works
- The Architecture Landscape
- Why Temporal Coherence Is the Hard Problem
- Multimodal Input: Why It Changes Everything
- Seedance 2.0: ByteDance's Cinematic Powerhouse
- Technical Architecture and Core Capabilities
- What Seedance 2.0 Does Better Than Anyone Else
- Real-World Use Cases
- The Copyright Controversy
- HappyHorse 1.0: The Leaderboard Challenger from Alibaba
- Technical Architecture
- What the Leaderboard Numbers Actually Mean
- The Open Source Question
- The Kuaishou Connection
- Seedance 2.0 vs HappyHorse 1.0: A Capability Comparison
- Where AI Video Generation Sits in 2026
- The Models That Did Not Make This Round
- What the Generative Video Stack Looks Like in Practice
- Practical Guidance for Teams Evaluating These Models
- The Takeaway
- Quick Reference: Platform Availability
The year 2026 has turned into the most consequential 12 months in the history of synthetic media. AI video generation has moved from producing jittery four-second clips with melting hands to delivering multi-shot cinematic sequences that professional colorists struggle to distinguish from camera footage. The technology stack underneath this leap is genuinely new: unified multimodal transformers, diffusion distillation that slashes sampling steps from 50 to 8, and joint audio-video generation that synchronizes dialogue, ambient sound, and music inside a single forward pass.
This article unpacks what is actually happening under the hood, ranks the capabilities that matter for real production workflows, and gives an honest picture of two models that have dominated leaderboards and industry conversations in early 2026: ByteDance's Seedance 2.0 and Alibaba's HappyHorse 1.0.
How Modern Text-to-Video Generation Actually Works
Understanding what separates a competent AI video model from a breakthrough one requires a brief tour of the architecture decisions that matter most. The field has converged on a short list of approaches, and knowing which a model uses tells you a lot about its strengths and failure modes.
The Architecture Landscape
Three architecture families currently compete for dominance in commercial video generation:
| Architecture | How It Works | Strengths | Weaknesses |
| Diffusion-only (UNet) | Iterative denoising via UNet backbone across latent frames | Strong visual quality, controllable via guidance | Slow inference, poor temporal coherence in long clips |
| DiT (Diffusion Transformer) | Patches of video frames treated as tokens; full attention across space and time | Excellent motion coherence, scales with compute | Memory-heavy; quadratic attention cost at high resolution |
| Unified Multimodal (Transfusion) | Single transformer ingesting text, image, audio, and video tokens jointly | Native cross-modal alignment, no post-processing audio sync | Training complexity; harder to fine-tune modularly |
| Autoregressive + Diffusion Hybrid | Autoregressive token prediction for coarse structure + diffusion refinement | Strong narrative coherence across shots | Higher latency, current models limited to short clips |
Most of the models people were using in 2024 used some variant of a UNet-based diffusion process. The shift to full-attention DiT architectures, and now to unified multimodal transformers, accounts for most of the quality improvement visible in 2026 outputs.
Why Temporal Coherence Is the Hard Problem
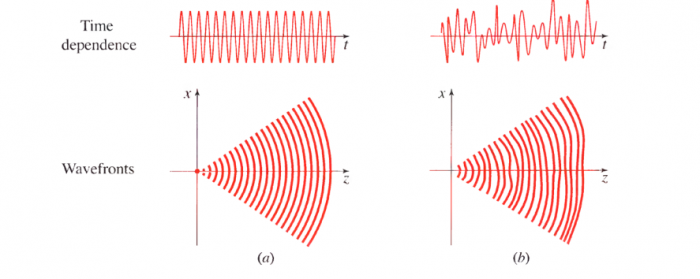
Generating a single photorealistic image frame is a solved problem. The hard part in video is maintaining identity, physics, and lighting consistency across 150 to 360 frames (6 to 15 seconds at 24fps). This is not just a matter of quality: it is a structural problem about how information flows through time in the model.
Earlier models handled this by generating frames semi-independently and relying on optical flow post-processing to smooth out jitter. Modern models solve it architecturally, using 3D attention mechanisms that attend across the time dimension as well as spatial dimensions, so every frame sees every other frame during generation. This is expensive in VRAM and compute, which is why the best open models currently require H100 GPUs with at least 48GB of memory.
Multimodal Input: Why It Changes Everything
The term "multimodal" gets thrown around loosely. In the context of video generation, it means something specific: the model can take reference images, video clips, and audio files as conditioning inputs alongside the text prompt, and it processes all of them inside the same attention mechanism rather than through separate encoders that feed embeddings downstream.
This matters because it allows creators to reference a specific character's face from one image, a camera movement from a reference clip, and a musical beat pattern from an audio file, and have all three constraints honored simultaneously in the output. That is simply not possible with models that treat these inputs as separate conditioning signals.
Seedance 2.0: ByteDance's Cinematic Powerhouse
| ORIGIN | Developed by ByteDance (parent company of TikTok). Initial version launched June 2025; Seedance 2.0 released February 2026. Went viral shortly after launch for ultra-realistic clips featuring recognizable cultural figures. |
Seedance 2.0 is the most commercially visible AI video model of early 2026. Since its February release, it has been integrated into platforms including Runway, Media.io, Higgsfield, and fal.ai, making it accessible to creators who never interact with an API directly. Its viral moment came fast: within days of launch, social media filled with clips of Friends characters reimagined as otters and action sequences pairing famous actors that would have cost millions to produce with a traditional crew.
What made those clips possible is not a single technique but a combination of architecture choices that ByteDance refined over eight months between v1 and v2.
Technical Architecture and Core Capabilities
Seedance 2.0 operates on a unified multimodal architecture that ingests text, image, audio, and video inputs inside a single model, rather than routing them through separate specialist encoders. A single generation pass can accept up to 9 reference images, 3 video clips totaling 15 seconds, and 3 audio files, all referenced by natural language in the prompt ("use [Image1] for the character's face, replicate the camera movement from [Video1]").
Key Technical Specifications
| Specification | Detail |
| Developer | ByteDance |
| Release Date | February 2026 (v1 June 2025) |
| Max Output Resolution | 2K (full version); 720p (current web app) |
| Max Clip Duration | 15 seconds (Seedance 2.0); 12 seconds (Lite) |
| Max Reference Inputs | 9 images + 3 video clips + 3 audio files |
| Audio Capabilities | Native joint audio-video; multilingual lip-sync |
| Camera Control | Director-level prompting: dolly, tilt, tracking, crane |
| API Access | Available via fal.ai; $0.30/second for 720p output |
| Geographic Availability | 100+ countries (US excluded as of April 2026) |
| Benchmark Position (T2V no-audio) | No. 2 on Artificial Analysis (overtaken by HappyHorse April 2026) |
What Seedance 2.0 Does Better Than Anyone Else
Character Consistency Across Shots
The most practical differentiator for production workflows is Seedance 2.0's ability to maintain face identity, clothing details, and even small text overlays across an entire multi-shot sequence. Earlier models required expensive post-production correction to stop characters from subtly drifting between scenes. Seedance 2.0 addresses this at the model level, not the post-processing level, by conditioning every generation step on a persistent character embedding derived from reference images.
Director-Level Camera Control
Prompting Seedance 2.0 for a "low-angle tracking shot that pulls back into a crane move at the moment the character speaks" actually produces that camera movement reliably. This is not trivial. Most video models treat camera motion as an emergent property of the generation process rather than a controllable output. Seedance 2.0 was explicitly trained on annotated cinematography data, which is why its camera behavior is more controllable than competitors.
Native Audio-Video Generation
Audio in Seedance 2.0 is not added after video generation via a separate model. It is produced jointly, meaning the waveform attends to the same token sequence as the visual frames. The practical result is that ambient sound, dialogue lip-sync, and music naturally align with on-screen action without requiring any post-processing to fix timing offsets.
Multi-Shot Storytelling
Rather than generating isolated 4-second clips, Seedance 2.0 supports structured multi-shot sequences where the user defines each scene by index in the prompt ("Scene 1@Image1: ... Scene 2@Image2: ..."). The model maintains narrative continuity and visual consistency between scenes, enabling the creation of short-form video content without a video editor.
Real-World Use Cases
| Industry | Use Case | Specific Capability Used |
| Marketing | Product launch videos from still images | Image-to-video + character/product consistency |
| Entertainment | Pre-visualization for film scenes | Director-level camera control + multi-shot sequencing |
| Education | Explainer videos with synchronized narration | Text-to-video + native audio lip-sync |
| Social Media | Trend-format video recreation with custom subjects | Reference video motion replication |
| Music | Music video generation synchronized to uploaded track | Audio reference conditioning + beat sync |
| E-commerce | Before/after product demonstrations | Multi-shot with consistent product identity |
The Copyright Controversy
| NOTICE | ByteDance was forced to pause the rollout of Seedance 2.0 in several markets following copyright disputes with major Hollywood studios and streaming platforms over the model's ability to replicate the likeness of named actors and reproduce stylistic elements of copyrighted properties. |
The controversy around Seedance 2.0 is inseparable from what makes it technically impressive. The model's hyper-realism, specifically its ability to produce footage that looks like it was shot on professional cameras with recognizable subjects, triggered immediate pushback from the entertainment industry. Rhett Reese, co-writer of Deadpool and Wolverine, posted publicly that the technology could allow a single person to produce a film indistinguishable from a Hollywood release.
The legal situation is unresolved. ByteDance has not disclosed its training data composition. Major studios have filed or indicated they are preparing to file infringement claims. This is worth tracking for any organization considering Seedance 2.0 as part of a commercial content pipeline.
HappyHorse 1.0: The Leaderboard Challenger from Alibaba
| ORIGIN | Developed by Alibaba's Taotian Future Life Lab (ATH AI Innovation Unit), led by Zhang Di, former VP of Kuaishou and technical lead of Kling AI. Appeared pseudonymously on the Artificial Analysis Video Arena on April 7, 2026. Alibaba confirmed development days later. |
HappyHorse 1.0 arrived with no press release, no paper, and no announced team. On April 7, 2026, the Artificial Analysis Video Arena logged a new pseudonymous model that had never appeared in any industry publication. Within 48 hours, it had climbed to the top of the blind preference leaderboard across the text-to-video and image-to-video (no-audio) categories, outperforming every established model by a margin that was not close.
The pattern of a pseudonymous model stress-testing blind leaderboards before a formal launch is a known technique in Chinese AI development. Pony Alpha in February 2026 turned out to be Z.ai's GLM-5 doing a pre-launch stress test on OpenRouter. HappyHorse followed the same template. Alibaba's CEO Eddie Wu confirmed the model's origin shortly after its leaderboard appearance.
Technical Architecture
HappyHorse 1.0 uses the Transfusion architecture, a hybrid approach that combines autoregressive discrete token prediction (the mechanism underlying language models) with continuous diffusion-based visual generation inside a single unified Transformer sequence. This is the same architectural family as Seedance 2.0, but with different design choices that appear to give HappyHorse an edge in visual fidelity at the cost of some audio-visual synchronization quality.
Confirmed Technical Specifications
| Specification | Detail |
| Developer | Alibaba (Taotian Future Life Lab / ATH AI Innovation Unit) |
| Technical Lead | Zhang Di (former VP Kuaishou, head of Kling AI) |
| Architecture | Transfusion (unified Transformer: autoregressive + diffusion) |
| Parameter Count | ~15 billion (single-stream, 40-layer transformer) |
| Attention Layout | First/last 4 layers: modality-specific; middle 32 layers: shared |
| Inference Speed | ~10 seconds per generation; ~38 seconds for 1080p on H100 |
| Distillation | DMD-2 distillation reduces sampling to 8 steps |
| Max Output Resolution | Native 1080p HD |
| Audio Lip-Sync Languages | Mandarin, Cantonese, English, Japanese, Korean, German, French |
| API Launch | Expected fal.ai, April 30, 2026 |
| Leaderboard Status (April 7, 2026) | T2V no-audio #1 (Elo 1333); I2V no-audio #1 (Elo 1392) |
What the Leaderboard Numbers Actually Mean
The Artificial Analysis Video Arena uses an Elo rating system based on blind human preference voting. Real users are shown two videos generated from the same prompt without knowing which model produced which, and they vote for the one they prefer. This is a harder test than self-reported benchmarks because it reflects actual human judgment rather than automated metrics.
| Category | HappyHorse 1.0 Elo | Seedance 2.0 Elo | Gap | Winner |
| T2V Without Audio | 1,333 | 1,273 | +60 points | HappyHorse 1.0 |
| I2V Without Audio | 1,392 | 1,355 | +37 points | HappyHorse 1.0 |
| T2V With Audio | 1,205 | 1,194 | +11 points | HappyHorse 1.0 |
| I2V With Audio | 1,161 | 1,160 | +1 point | Effectively tied |
| CAVEAT | Elo scores for newly added models are more volatile than established ones. Seedance 2.0 had over 7,500 vote samples at the time HappyHorse appeared. HappyHorse's sample count was smaller and had not been publicly disclosed, meaning rankings will shift as more votes accumulate. |
The 60-point Elo gap in text-to-video without audio is significant. In the Elo system used by Artificial Analysis, a gap of that size represents a meaningful difference in human preference under blind conditions, not a marginal edge. The audio categories tell a different story: Seedance 2.0 and HappyHorse are essentially equivalent when audio quality is factored into the preference vote.
The Open Source Question
HappyHorse's marketing materials claim the model will be fully open source, with base model weights, distilled model weights, super-resolution model weights, and inference code all released. As of April 2026, no weights were available on HuggingFace or GitHub; the published links showed "coming soon" placeholders.
This matters for several categories of users. Organizations that need to run video generation on-premise for data privacy reasons, researchers who want to study the architecture, and developers who want to fine-tune on proprietary datasets all need weight access to do their work. The claim is out there; the delivery timeline is not.
The Kuaishou Connection
The team lead, Zhang Di, rejoined Alibaba in late 2025 after serving as VP at Kuaishou, where he oversaw the development of Kling, another competitive Chinese video generation model. The Kling connection matters because Kling was itself a benchmark leader when it launched, and Zhang Di's involvement suggests HappyHorse was built with direct knowledge of what architectural decisions produced Kling's strengths. The middle 32 layers of HappyHorse's transformer share parameters across all modalities, a design that suggests the team was explicitly optimizing for cross-modal efficiency rather than bolting modules together.
Seedance 2.0 vs HappyHorse 1.0: A Capability Comparison
Both models are genuinely excellent and represent the current ceiling of consumer-accessible AI video generation. The decision between them depends on specific workflow requirements.
| Capability | Seedance 2.0 | HappyHorse 1.0 |
| Visual Quality (no audio) | Excellent | Best in class (April 2026 leaderboard) |
| Max Resolution | 2K | 1080p native |
| Audio-Video Sync | Strong (native joint generation) | On par with Seedance in audio categories |
| Multilingual Lip-Sync | Yes (several languages) | 7 languages incl. Cantonese, Korean |
| Character Consistency | Excellent across multi-shot sequences | Strong; full data not yet published |
| Camera Control | Director-level via natural language prompts | Controllable; less documented |
| Max Clip Duration | 15 seconds | 15 seconds (paid) |
| API Availability | fal.ai, Runway, Media.io, Higgsfield | fal.ai (expected April 30, 2026) |
| Pricing (API) | $0.30/sec for 720p | Not yet announced |
| Geographic Access | 100+ countries (US excluded) | To be confirmed at launch |
| Open Source | No | Claimed; weights not yet released |
| Developer | ByteDance | Alibaba (ATH AI Innovation Unit) |
| Training Transparency | Not disclosed | Not disclosed |
| Maturity | 9+ months in production | Early access / pre-launch |
The single most important practical difference is availability. Seedance 2.0 has been in production on multiple platforms for months. It has a pricing model, documented API behavior, and a track record of failure modes that developers understand. HappyHorse 1.0 has a leaderboard position and a launch date. For teams evaluating these models for integration, that asymmetry matters more than a 60-point Elo gap.
Where AI Video Generation Sits in 2026
The Models That Did Not Make This Round
Several other models competed seriously for top positions in early 2026 and deserve mention.
| Model | Developer | Distinction | Status (April 2026) |
| Kling 3.0 Pro | Kuaishou | Strong realism; prior benchmark leader | Active; losing T2V ground to HappyHorse |
| Veo 3 | Google DeepMind | Best physics simulation; highest training compute | Limited API access |
| PixVerse V6 | PixVerse | Best in class for animation and stylized content | Active; strong niche position |
| Wan 2.6 | Various | Open source; solid general quality | Available; below top tier on leaderboard |
| Sora 2 | OpenAI | Social-integrated video creation | Discontinued early 2026; strategic pivot to AGI |
| Hailuo | MiniMax | Competitive Chinese model; strong motion quality | Active |
OpenAI's exit from video generation is the most consequential structural shift in the competitive landscape. The decision to discontinue Sora and redirect resources toward coding tools and AGI development left a gap that ByteDance and Alibaba are actively filling. For Western enterprise customers who prefer US-headquartered vendors, Google's Veo 3 is currently the primary alternative, though its access remains restricted.
What the Generative Video Stack Looks Like in Practice
Production pipelines that use AI video generation in 2026 are not replacing traditional video production end to end. They are replacing specific, expensive steps:
● Pre-visualization and storyboarding, where iterative AI generation replaces hand-drawn animatics at a fraction of the cost and timeline
● B-roll and cutaway generation, where short scenic clips that would require location shoots are generated from text prompts
● Social content at scale, where brands need dozens of short-form video variations for A/B testing across platforms
● Localization, where generated lip-sync allows the same video to be re-voiced into multiple languages without re-shooting
● Early-stage concept pitches, where a director can present near-finished-quality footage for greenlight decisions instead of rough boards
The use cases that remain firmly in the domain of traditional production are complex narrative features requiring sustained performance from named actors, live events, and documentary content requiring real-world authenticity. These are not going away. But the percentage of commercial video production that can be partially or fully automated is growing faster than most industry observers projected even 18 months ago.
Practical Guidance for Teams Evaluating These Models
| FOR AGENCIES | Start with Seedance 2.0 on Runway or Media.io. The platform integration means no infrastructure investment, pricing is predictable, and the model's multi-shot storytelling capability is mature enough for client deliverables. Evaluate HappyHorse 1.0 after its fal.ai API launches and you have production data. |
| FOR DEVELOPERS | Seedance 2.0 is available on fal.ai today at $0.30/second. The API supports multimodal reference inputs, video extension, and video editing endpoints. Budget for HappyHorse 1.0 evaluation in Q2 2026 once weights or API access is confirmed. If open-source weights actually ship, HappyHorse will be significant for on-premise deployments. |
| FOR ENTERPRISE | Neither model has a clean answer on training data provenance or copyright clearance status. Any commercial use should involve a legal review, particularly for content that could involve identifiable likeness or stylistic replication of copyrighted works. The ByteDance geography restriction (US excluded) is a hard constraint for US-based operations. |
The Takeaway
The gap between AI video generation and professional cinematography has not closed completely, but in early 2026 it narrowed faster than the previous five years combined. Seedance 2.0 and HappyHorse 1.0 are the sharpest illustrations of where the technology actually is: both models produce footage that requires careful frame-by-frame inspection to identify as synthetic, both support multi-modal inputs that give creators meaningful control over output, and both arrive from organizations with the compute resources and training data infrastructure to continue improving rapidly.
Seedance 2.0 is the model with the production track record. It has a documented API, a pricing model, real users who have shipped real work with it, and a known failure mode set. HappyHorse 1.0 has a better leaderboard position in pure visual quality, a compelling architecture story about its Transfusion design, and the institutional weight of Alibaba's e-commerce and advertising infrastructure as a distribution channel once it launches commercially.
The competition between these two models, and between the broader set of Chinese and US AI video labs, is producing a quality improvement curve that is steep enough to make projections about the technology look obsolete within a quarter. The practical implication for any organization that produces video content at scale is not "should we evaluate AI video generation" but “how do we build evaluation and integration capacity fast enough to stay current.”
Quick Reference: Platform Availability
| Platform | Seedance 2.0 | HappyHorse 1.0 | Pricing Model |
| Runway | Available | Not yet | Subscription + credits |
| fal.ai (API) | Available | Expected April 30 | $0.30/sec (Seedance); TBD |
| Media.io | Available | Not yet | Subscription |
| Higgsfield | Available (all plans) | Not yet | Plan-based |
| WaveSpeedAI | Available | Not yet | Per-generation credits |
| Direct Web App | seedance2.app (720p, 15s) | No confirmed official app | Credits-based |
Post Comments
Be the first to post comment!
Related Articles




